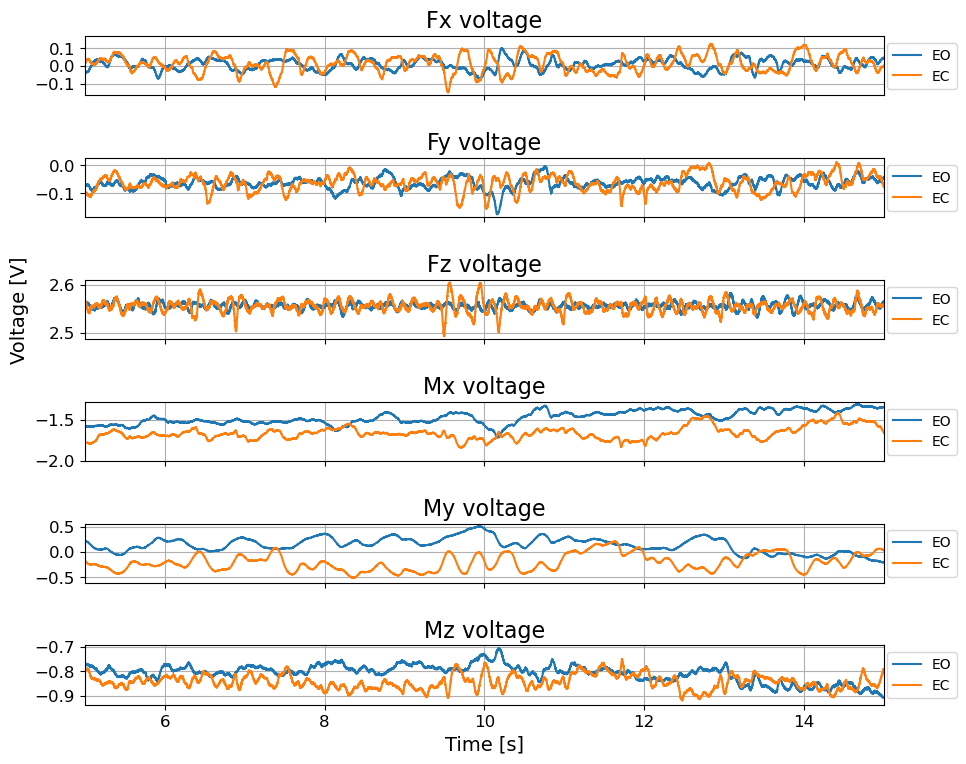
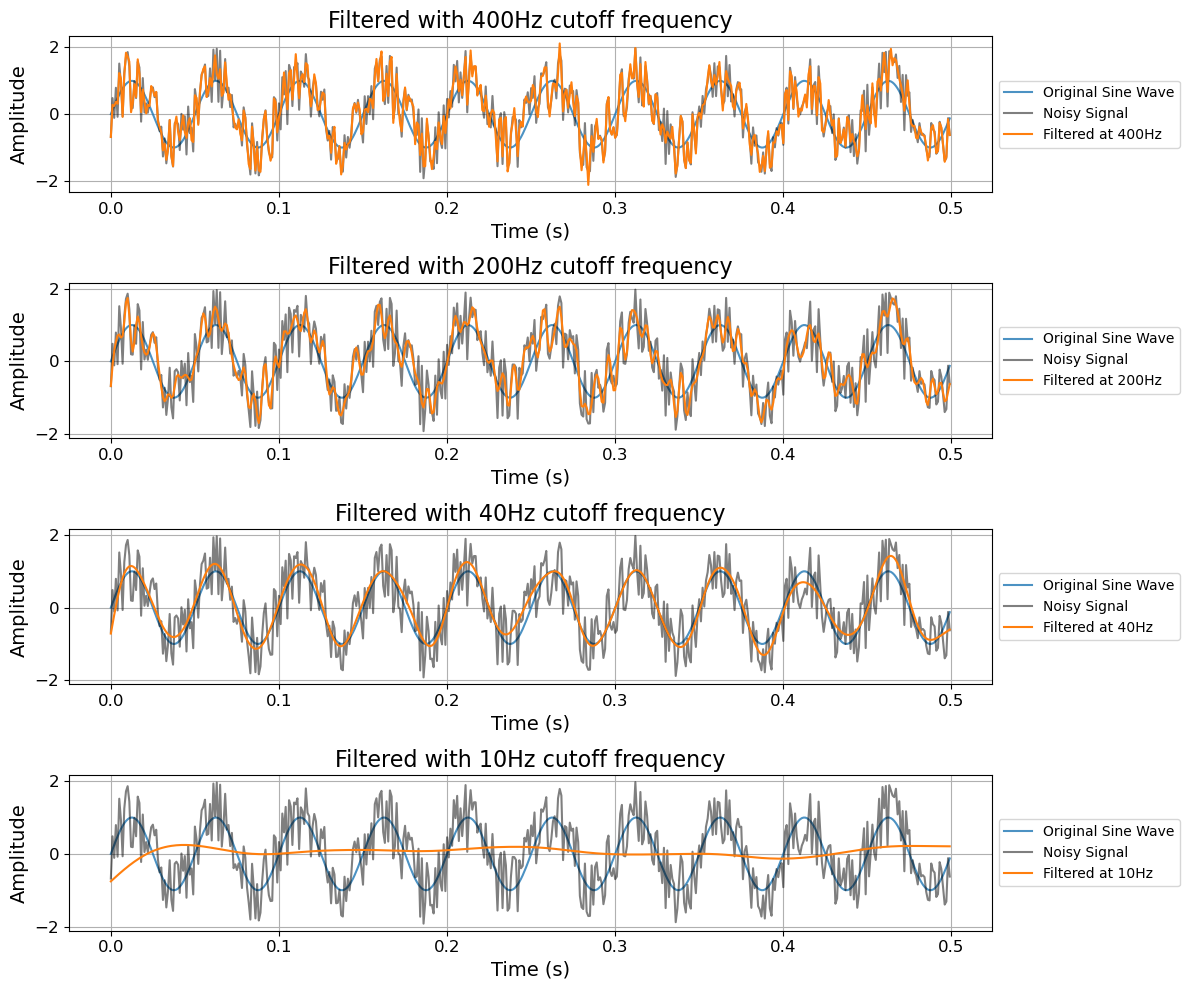
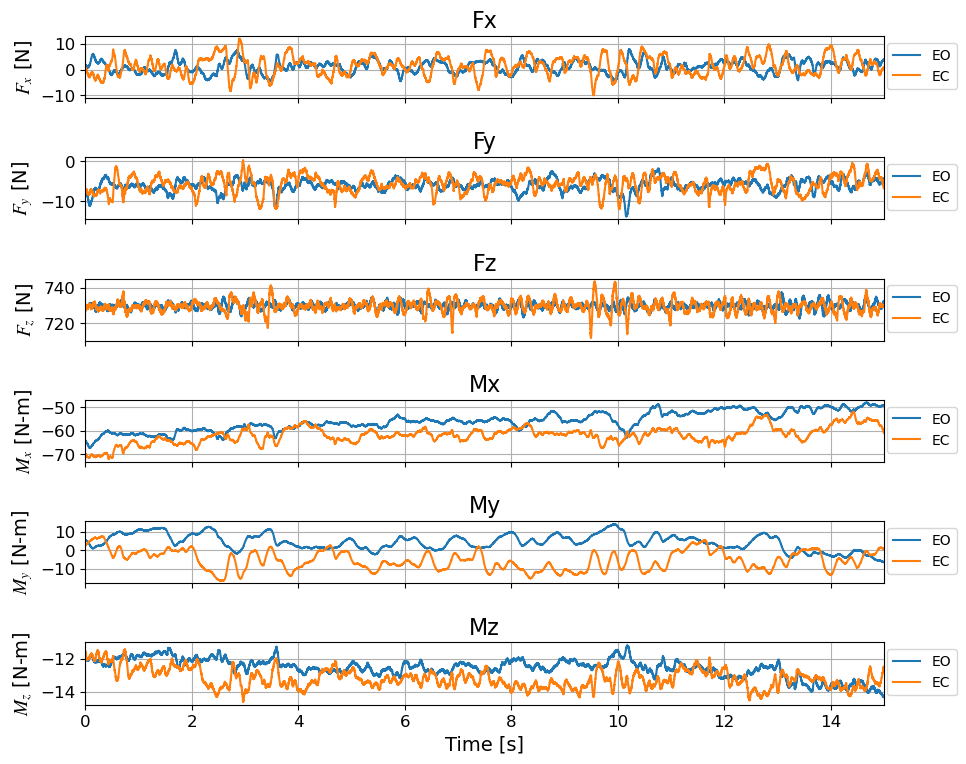
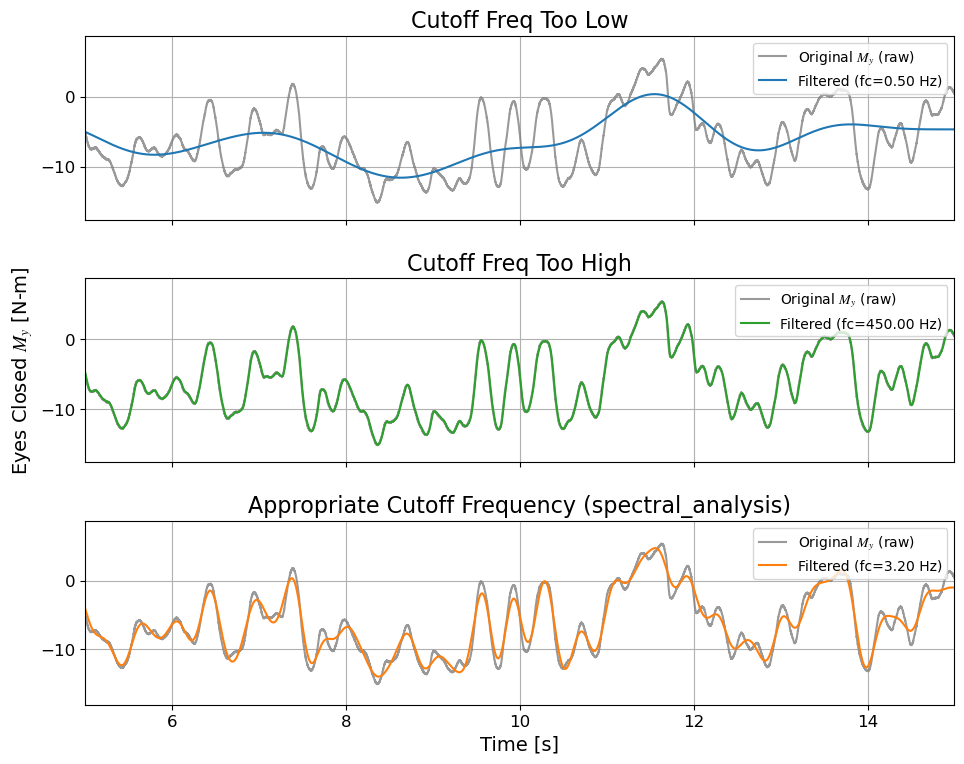
# This is a helper function for filtering timeseries data
def filter_timeseries_data(
data: Union[List[float], np.ndarray, pd.DataFrame, pd.Series],
sampling_freq: float,
custom_cutoff_frequency: Optional[float] = None,
threshold: float = 99,
plot: bool = False,
rolling_window: int = 10,
butter_order: int = 4,
nan_policy: str = "interpolate",
nan_fill_value: Optional[float] = None,
) -> Union[List[float], np.ndarray, pd.DataFrame, pd.Series]:
"""Apply a low-pass Butterworth filter to time-series data.
The function accepts lists, 1-D NumPy arrays, 2-D NumPy arrays with shape
(n_samples, n_channels), pandas Series, or pandas DataFrame. When
``custom_cutoff_frequency`` is not given, a cutoff frequency is estimated
per channel using :func:`spectral_analysis` with the provided ``threshold``.
Parameters
----------
data:
Input time-series. Supported types:
- ``list`` (treated as 1-D signal, returns ``list``)
- ``np.ndarray`` (1-D or 2-D). For 2-D arrays filtering is applied to
each column and the resulting array has the same shape.
- ``pandas.Series`` (returns ``pandas.Series`` with the same index/name)
- ``pandas.DataFrame`` (filters each column and returns a DataFrame
preserving index and columns)
sampling_freq:
Sampling frequency in Hz.
custom_cutoff_frequency:
If provided, this scalar cutoff frequency (Hz) is used for all
channels. Otherwise, the cutoff is estimated independently per channel
using ``spectral_analysis`` and the given ``threshold``.
threshold:
Cumulative power percentage (0-100) used by ``spectral_analysis`` when
estimating cutoffs.
plot:
If True, enables plotting inside the underlying ``spectral_analysis``
calls and shows the PSD/cumulative plots. Plotting is only triggered
when cutoffs are estimated automatically (i.e., ``custom_cutoff_frequency``
is ``None``). For multi-channel inputs this may display one figure per
channel and can be slow or produce many windows; set ``plot=False`` to
suppress plotting.
rolling_window:
Integer window size used to apply a simple moving average to any
pandas.Series inputs before filtering to reduce very short-term noise.
butter_order:
Integer order of the Butterworth filter. Defaults to 4 for a
4th-order low-pass filter. Increasing the order makes the filter
steeper but may introduce more ringing/artifacts.
nan_policy:
How to handle NaN values in the input data. Options:
- ``'raise'`` (default): raise ``ValueError`` if NaNs are present.
- ``'interpolate'``: interpolate NaNs along the time axis (linear
interpolation). Works for arrays and pandas objects.
- ``'fill'``: replace NaNs with ``nan_fill_value`` (must be provided).
nan_fill_value:
Value used to fill NaNs when ``nan_policy=='fill'``. If None and
``nan_policy=='fill'``, a ValueError is raised.
Notes on filtering behavior
--------------------------
- The filter is designed with ``scipy.signal.butter`` using ``butter_order``
and applied with ``filtfilt`` for zero-phase filtering when possible.
For very short signals where ``filtfilt`` cannot be used the code falls
back to ``lfilter`` and logs a WARNING; this introduces a phase shift
relative to zero-phase filtering.
- ``butter_order`` is validated to be an integer >= 1.
Returns
-------
list | np.ndarray | pandas.Series | pandas.DataFrame
Filtered data with the same type and shape as the input. For numpy
arrays, columns are treated along axis=1 (i.e., shape (n_samples,
n_channels)).
Raises
------
ValueError
If ``data`` is not one of the supported types.
Notes
-----
- The filter is a Butterworth low-pass filter implemented via
``scipy.signal.butter`` and applied with ``filtfilt`` for zero-phase
filtering. The default order is 4 (4th-order) but this can be changed
using the ``butter_order`` parameter.
- If the estimated or provided cutoff is >= Nyquist (fs/2) it is clamped
to 95% of Nyquist. If it is <= 0 it is clamped to 5% of Nyquist. These
behaviours are intentional to avoid invalid filter designs.
- NaN handling: use the ``nan_policy`` parameter to control behavior.
Options are ``'raise'`` (default), ``'interpolate'``, or ``'fill'``.
When ``'fill'`` is selected, ``nan_fill_value`` must be provided.
- Estimating cutoffs via spectral analysis for many channels may be slow;
provide ``custom_cutoff_frequency`` when possible for performance.
Examples
--------
Filter a 1-D numpy signal:
>>> filtered = filter_timeseries_data(np.array(x), sampling_freq=1000)
Filter a pandas DataFrame (each column filtered independently):
>>> filtered_df = filter_timeseries_data(df, sampling_freq=200)
"""
# Accept list, ndarray, DataFrame, Series
input_type = None
if isinstance(data, list):
# Convert list to numpy array
data = np.array(data)
input_type = 'list'
elif isinstance(data, np.ndarray):
input_type = 'ndarray'
elif isinstance(data, pd.DataFrame):
input_type = 'dataframe'
elif isinstance(data, pd.Series):
input_type = 'series'
else:
raise ValueError(
"Unsupported data type. Please provide a list, NumPy array, pandas DataFrame, or pandas Series.")
fs = float(sampling_freq)
# Validate butter_order
if not isinstance(butter_order, int) or butter_order < 1:
raise ValueError("butter_order must be an integer >= 1")
# Validate nan handling policy
if nan_policy not in ("raise", "interpolate", "fill"):
raise ValueError("nan_policy must be one of 'raise', 'interpolate', or 'fill'")
# Handle NaNs according to policy. For pandas objects use pandas methods;
# for numpy arrays use interpolation via numpy where appropriate.
if input_type in ("dataframe", "series"):
if nan_policy == "raise":
if (isinstance(data, pd.DataFrame) and data.isna().values.any()) or (
isinstance(data, pd.Series) and data.isna().any()
):
_LOGGER.debug("NaNs detected in pandas input and nan_policy='raise' -> raising ValueError")
raise ValueError("NaN values found in input; set nan_policy to 'interpolate' or 'fill' to handle them")
elif nan_policy == "interpolate":
# Linear interpolation along the index (time axis)
if isinstance(data, pd.DataFrame):
data = data.interpolate(axis=0).ffill().bfill()
_LOGGER.debug("Interpolated NaNs in pandas DataFrame input (axis=0) and applied ffill/bfill for edges")
_LOGGER.info("Interpolated NaNs in pandas DataFrame input (nan_policy='interpolate')")
else:
data = data.interpolate().ffill().bfill()
_LOGGER.debug("Interpolated NaNs in pandas Series input and applied ffill/bfill for edges")
_LOGGER.info("Interpolated NaNs in pandas Series input (nan_policy='interpolate')")
else: # fill
if nan_fill_value is None:
_LOGGER.debug("nan_policy='fill' but nan_fill_value is None -> raising ValueError")
raise ValueError("nan_fill_value must be provided when nan_policy=='fill'")
data = data.fillna(nan_fill_value)
_LOGGER.debug("Filled NaNs in pandas input with value=%s", nan_fill_value)
_LOGGER.info("Filled NaNs in pandas input with value=%s (nan_policy='fill')", nan_fill_value)
elif input_type in ("ndarray", "list"):
arr = np.asarray(data, dtype=float)
if arr.ndim == 1:
if np.isnan(arr).any():
if nan_policy == "raise":
_LOGGER.debug("NaNs detected in 1D ndarray and nan_policy='raise' -> raising ValueError")
raise ValueError("NaN values found in input array; set nan_policy to 'interpolate' or 'fill' to handle them")
elif nan_policy == "interpolate":
idx = np.arange(arr.size)
mask = np.isfinite(arr)
if not mask.all():
arr = np.interp(idx, idx[mask], arr[mask])
_LOGGER.debug("Interpolated NaNs in 1D ndarray input using numpy.interp")
_LOGGER.info("Interpolated NaNs in 1D ndarray input (nan_policy='interpolate')")
else: # fill
if nan_fill_value is None:
_LOGGER.debug("nan_policy='fill' but nan_fill_value is None -> raising ValueError")
raise ValueError("nan_fill_value must be provided when nan_policy=='fill'")
arr = np.where(np.isnan(arr), nan_fill_value, arr)
_LOGGER.debug("Filled NaNs in 1D ndarray input with value=%s", nan_fill_value)
_LOGGER.info("Filled NaNs in 1D ndarray input with value=%s (nan_policy='fill')", nan_fill_value)
data = arr
else:
# 2D array: process each column
if np.isnan(arr).any():
if nan_policy == "raise":
_LOGGER.debug("NaNs detected in 2D ndarray and nan_policy='raise' -> raising ValueError")
raise ValueError("NaN values found in input array; set nan_policy to 'interpolate' or 'fill' to handle them")
elif nan_policy == "interpolate":
arr2 = arr.copy()
for i in range(arr2.shape[1]):
col = arr2[:, i]
idx = np.arange(col.size)
mask = np.isfinite(col)
if not mask.all():
arr2[:, i] = np.interp(idx, idx[mask], col[mask])
data = arr2
n_nans = int(np.isnan(arr).sum())
_LOGGER.debug("Interpolated NaNs in 2D ndarray input for %d columns", arr2.shape[1])
_LOGGER.info("Interpolated %d NaNs in 2D ndarray input across %d columns (nan_policy='interpolate')", n_nans, arr2.shape[1])
else:
if nan_fill_value is None:
_LOGGER.debug("nan_policy='fill' but nan_fill_value is None -> raising ValueError")
raise ValueError("nan_fill_value must be provided when nan_policy=='fill'")
data = np.where(np.isnan(arr), nan_fill_value, arr)
_LOGGER.debug("Filled NaNs in 2D ndarray input with value=%s", nan_fill_value)
n_nans = int(np.isnan(arr).sum())
_LOGGER.info("Filled %d NaNs in 2D ndarray input with value=%s (nan_policy='fill')", n_nans, nan_fill_value)
def apply_filter(column, cutoff_frequency):
# Ensure cutoff_frequency is within (0, fs/2)
nyquist = fs / 2.0
if cutoff_frequency >= nyquist:
# Set to 95% of Nyquist if above or equal
cutoff_frequency = nyquist * 0.95
if cutoff_frequency <= 0:
# Set to a small positive value if non-positive
cutoff_frequency = nyquist * 0.05
# Design Butterworth filter with configurable order
b, a = butter(N=butter_order, Wn=cutoff_frequency,
btype="low", fs=fs, output="ba")
# Smooth very short-term noise for pandas Series inputs
if isinstance(column, pd.Series):
column = column.rolling(window=rolling_window, min_periods=1).mean()
# Work on numpy array copy for length/pad checks
col_arr = np.asarray(column, dtype=float)
# filtfilt requires length > padlen where padlen = 3*(max(len(a), len(b)) - 1)
padlen = 3 * (max(len(a), len(b)) - 1)
if col_arr.size <= padlen:
# Fallback to lfilter with a warning (introduces phase shift)
_LOGGER.warning(
"Signal length %d <= padlen %d for filtfilt (order=%d). Falling back to lfilter which introduces phase shift.",
col_arr.size,
padlen,
butter_order,
)
return lfilter(b, a, col_arr)
# Zero-phase filtering
return filtfilt(b, a, col_arr)
if custom_cutoff_frequency is not None:
cutoff_frequency = custom_cutoff_frequency
if input_type == 'ndarray':
if custom_cutoff_frequency is None:
_LOGGER.info("Automatic cutoff estimation for %d channels (threshold=%s%%)", data.shape[1], threshold)
cutoff_frequencies = [float(spectral_analysis(
data=column, sampling_freq=sampling_freq, threshold=threshold, plot=plot)) for column in data.T]
else:
cutoff_frequencies = [cutoff_frequency] * data.shape[1]
filtered_data = np.array([apply_filter(column, cf)
for column, cf in zip(data.T, cutoff_frequencies)]).T
try:
cutoffs = np.asarray(cutoff_frequencies, dtype=float)
_LOGGER.info(
"Filtering complete for %d channels (butter_order=%d). Cutoff summary: min=%.3gHz median=%.3gHz max=%.3gHz",
cutoffs.size,
butter_order,
np.nanmin(cutoffs),
np.nanmedian(cutoffs),
np.nanmax(cutoffs),
)
except Exception:
_LOGGER.info("Filtering complete (ndarray input).")
return filtered_data
elif input_type == 'dataframe':
if custom_cutoff_frequency is None:
_LOGGER.info("Automatic cutoff estimation for %d channels (threshold=%s%%)", len(data.columns), threshold)
cutoff_frequencies = {column: float(spectral_analysis(
data=data[column], sampling_freq=sampling_freq, threshold=threshold, plot=plot)) for column in data.columns}
else:
cutoff_frequencies = {
column: cutoff_frequency for column in data.columns}
filtered_data = data.apply(lambda column: apply_filter(
column, cutoff_frequencies[column.name]))
try:
cutoffs = np.asarray(list(cutoff_frequencies.values()), dtype=float)
_LOGGER.info(
"Filtering complete for %d channels (butter_order=%d). Cutoff summary: min=%.3gHz median=%.3gHz max=%.3gHz",
cutoffs.size,
butter_order,
np.nanmin(cutoffs),
np.nanmedian(cutoffs),
np.nanmax(cutoffs),
)
except Exception:
_LOGGER.info("Filtering complete (DataFrame input).")
return filtered_data
elif input_type == 'series':
if custom_cutoff_frequency is None:
cutoff_frequency = float(spectral_analysis(
data=data, sampling_freq=sampling_freq, threshold=threshold, plot=plot))
filtered_data = apply_filter(data, cutoff_frequency)
_LOGGER.info("Filtering complete for 1 channel (butter_order=%d). Cutoff=%.3g Hz", butter_order, cutoff_frequency)
return pd.Series(filtered_data, index=data.index, name=data.name)
elif input_type == 'list':
# Treat as 1D array
if custom_cutoff_frequency is None:
cutoff_frequency = float(spectral_analysis(
data=data, sampling_freq=sampling_freq, threshold=threshold, plot=plot))
filtered_data = apply_filter(pd.Series(data), cutoff_frequency)
_LOGGER.info("Filtering complete for 1 channel (butter_order=%d). Cutoff=%.3g Hz", butter_order, cutoff_frequency)
return filtered_data.tolist()